Algoritmo Cache
Um algoritmo Cache é um algoritmo utilizado para gerir uma cache ou grupo de dados. Quando a cache está cheia, ele decide qual o item que deve ser apagado da cache. A palavra taxa de acerto descreve a frequência com que um pedido pode ser servid…
Um algoritmo Cache é um algoritmo utilizado para gerir uma cache ou grupo de dados. Quando a cache está cheia, ele decide qual o item que deve ser apagado da cache. A palavra taxa de acerto descreve a frequência com que um pedido pode ser servido a partir da cache. O termo latência descreve durante quanto tempo um item em cache pode ser obtido. As aloritmos de cache são um compromisso entre a taxa de acerto e a latência.
- O algoritmo de cache mais eficiente seria sempre descartar a informação que não será necessária durante o maior período de tempo no futuro. Este resultado óptimo é referido como o algoritmo óptimo de Belady ou o algoritmo clarividente. Uma vez que é geralmente impossível prever até que ponto no futuro a informação será necessária, isto não é geralmente implementável na prática. O mínimo prático só pode ser calculado após a experimentação, e pode-se comparar a eficácia do algoritmo de cache realmente escolhido com o mínimo óptimo.
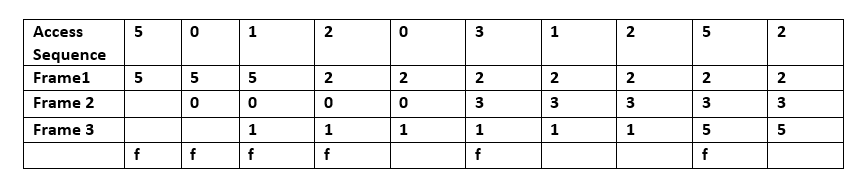
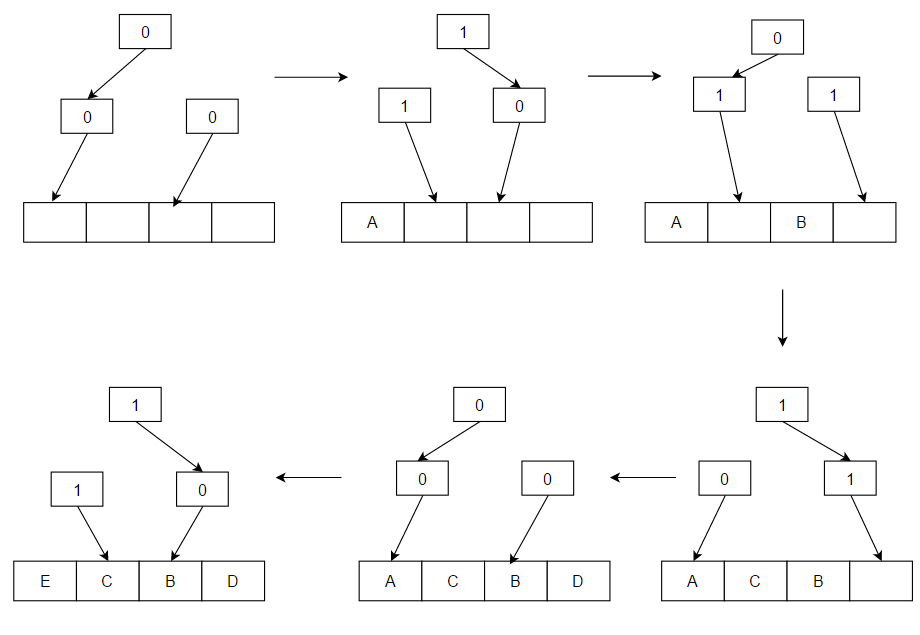
- Menos Usado Recentemente (LRU): apaga primeiro os artigos menos usados recentemente. Este algoritmo exige que se mantenha um registo do que foi utilizado quando. Isto é caro se se quiser ter a certeza de que o algoritmo descarta sempre o item menos recentemente utilizado. As implementações gerais desta técnica requerem que se mantenha "bits de idade" para linhas de cache e que se rastreie a linha de cache "Menos Usado Recentemente" com base nos bits de idade. Em tal implementação, sempre que uma linha de cache é utilizada, a idade de todas as outras linhas de cache muda. A LRU é na realidade uma família de algoritmos de cache com membros, incluindo: 2Q por Theodore Johnson e Dennis Shasha e LRU/K por Pat O'Neil, Betty O'Neil e Gerhard Weikum.
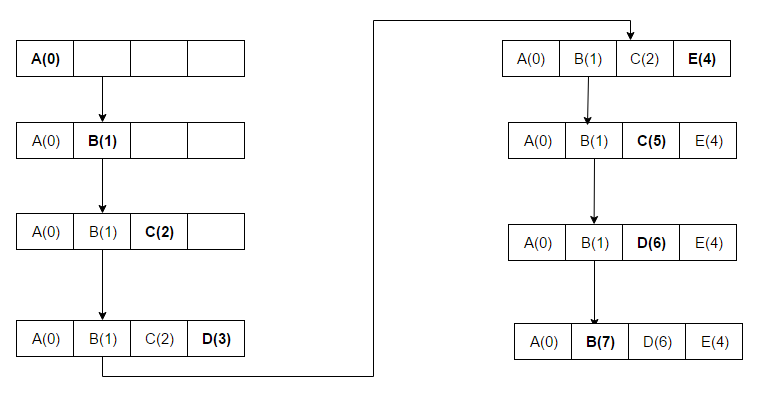
- Utilizado mais recentemente (MRU): Este algoritmo apaga primeiro os artigos mais recentemente utilizados. Este mecanismo de cache é normalmente utilizado para caches de memória de bases de dados.
- Pseudo-LRU (PLRU): Existem certos casos em que a LRU é muito difícil de implementar. Nesses casos, pode ser suficiente saber que na maioria dos casos, um dos artigos menos utilizados é eliminado. O algoritmo PLRU pode ser aí utilizado, porque só precisa de um bit por item de cache para funcionar.
- Conjunto associativo de 2 vias: para caches de CPU de alta velocidade onde até a PLRU é demasiado lenta. O endereço de um novo item é utilizado para calcular uma de duas localizações possíveis na cache onde é permitido ir. A LRU dos dois é descartada. Isto requer um bit por cada par de linhas de cache, para indicar qual das duas foi a menos utilizada recentemente.
- Cache directamente mapeada: para as caches de CPU de maior velocidade onde mesmo as caches associativas de 2 vias são demasiado lentas. O endereço do novo item é utilizado para calcular o único local na cache para onde é permitido ir. O que quer que lá estivesse antes, é descartado.
- Menos Usado com Mínima Frequência (LFU): LFU conta a frequência com que um item é necessário. Os que são utilizados com menos frequência são descartados primeiro.
- Cache de Substituição Adaptativa (ARC): equilíbrio constante entre LRU e LFU, para melhorar o resultado combinado.
- Algoritmo de caching Multi Queue (MQ): (por Y. Zhou J.F. Philbin e Kai Li).
Outras coisas a considerar:
- Artigos com custos diferentes: manter artigos que são caros de obter, por exemplo, aqueles que levam muito tempo a obter.
- Itens que ocupam mais cache: Se os itens tiverem tamanhos diferentes, a cache pode querer descartar um item grande para armazenar vários itens mais pequenos.
- Itens que expiram com o tempo: Alguns caches guardam informações que expiram (por exemplo, uma cache de notícias, uma cache DNS, ou uma cache de um navegador web). O computador pode descartar itens porque estão expirados. Dependendo do tamanho da cache, não poderá ser necessário mais nenhum algoritmo de cache para descartar itens.
Existem também vários algoritmos para manter a coerência do cache. Isto aplica-se apenas a situações em que múltiplas caches independentes são utilizadas para os mesmos dados (por exemplo, múltiplos servidores de bases de dados actualizando o único ficheiro de dados partilhado).
Galeria de imagens
7 Imagens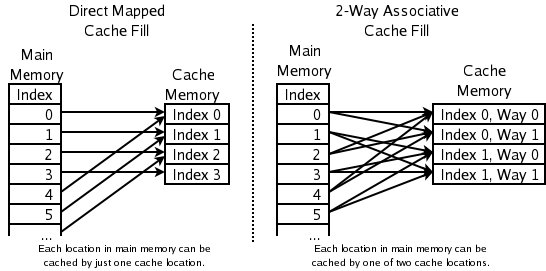




Perguntas e respostas
P: O que é um Algoritmo Cache?
R: Um algoritmo Cache é um algoritmo usado para administrar um cache ou grupo de dados. Ele decide qual item deve ser apagado do cache quando ele estiver cheio.
P: O que é taxa de acerto?
R: A taxa de acertos descreve com que freqüência um pedido pode ser servido a partir do cache.
P: O que descreve a latência?
R: A latência descreve por quanto tempo um item armazenado em cache pode ser obtido.
P: Qual é o algoritmo ideal do Belady?
R: O algoritmo ótimo do Belady, também conhecido como algoritmo clarividente, é um algoritmo de cache eficiente que sempre descarta a informação que não será necessária por mais tempo no futuro. Esse resultado geralmente não pode ser implementado na prática, porque exige uma previsão do que será necessário no futuro.
P: Como funciona a LRU (LRU), o "Menos Usado Recentemente"?
R: A LRU apaga primeiro os itens menos usados recentemente e exige que se mantenha o controle do que foi usado quando se usa "pedaços de idade" para cada linha de cache e se rastreia qual foi usada menos recentemente com base nos pedaços de idade. Toda vez que uma linha de cache é usada, todas as outras linhas de cache são mudadas de acordo com a idade.
P: Como funciona o "Most Recently Used" (MRU)?
R: MRU apaga primeiro os itens usados mais recentemente e esse mecanismo de cache é comumente usado para caches de memória de banco de dados.
P: Que outros algoritmos existem para manter a coerência do cache?
R: Vários algoritmos existem para manter a coerência do cache quando múltiplos caches independentes estão sendo usados para dados compartilhados, tais como múltiplos servidores de banco de dados atualizando um único arquivo de dados compartilhado.
Artigos relacionados
Autor
AlegsaOnline.com Algoritmo Cache Leandro Alegsa
URL: https://pt.alegsaonline.com/art/15882
Fontes
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org