Microarquitetura
Na engenharia informática, a microarquitetura (às vezes abreviada para µarch ou uarch) é uma descrição do circuito elétrico de um computador, unidade central de processamento ou processador de sinal digital que é suficiente para descrever comple…
Na engenharia informática, a microarquitetura (às vezes abreviada para µarch ou uarch) é uma descrição do circuito elétrico de um computador, unidade central de processamento ou processador de sinal digital que é suficiente para descrever completamente o funcionamento do hardware.
Os estudiosos usam o termo "organização de computadores" enquanto as pessoas da indústria de computadores dizem com mais freqüência: "microarquitetura". A microarquitetura e a arquitetura do conjunto de instruções (ISA), juntas, constituem o campo da arquitetura de computadores.
Galeria de imagens
1 Imagem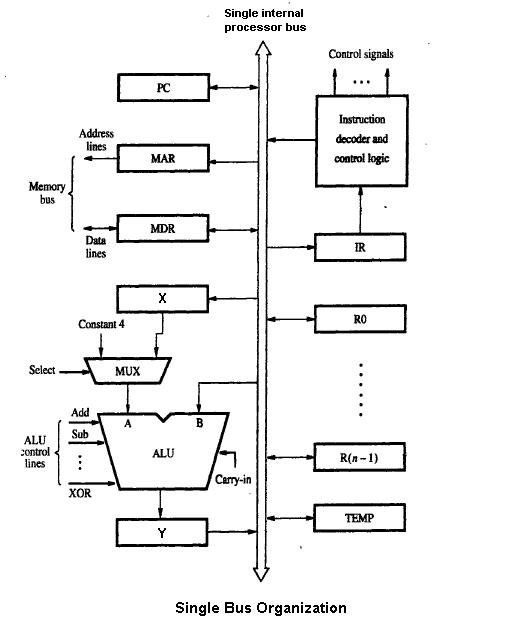
Origem do termo
Os computadores têm usado a microprogramação da lógica de controle desde os anos 50. A CPU decodifica as instruções e envia sinais pelos caminhos apropriados por meio de interruptores transistor. Os bits dentro das palavras do microprograma controlavam o processador ao nível dos sinais elétricos.
O termo: microarquitetura foi usado para descrever as unidades que eram controladas pelas palavras do microprograma, em contraste com o termo: "arquitetura", que era visível e documentada para os programadores. Embora a arquitetura geralmente tivesse que ser compatível entre as gerações de hardware, a microarquitetura subjacente podia ser facilmente alterada.
Relação com a arquitetura do conjunto de instruções
A microarquitetura está relacionada, mas não é a mesma que a arquitetura do conjunto de instruções. A arquitetura do conjunto de instruções está próxima ao modelo de programação de um processador como visto por um programador ou compilador de linguagem de montagem, que inclui o modelo de execução, registros de processador, modos de endereço de memória, formatos de endereço e dados, etc. A microarquitetura (ou organização de computadores) é principalmente uma estrutura de nível inferior e, portanto, gerencia um grande número de detalhes que estão ocultos no modelo de programação. Ela descreve as partes internas do processador e como elas trabalham em conjunto a fim de implementar a especificação arquitetônica.
Os elementos microarchitectuais podem ser tudo, desde uma única porta lógica, até registros, tabelas de pesquisa, multiplexadores, contadores, etc., até ALUs completas, FPUs e até mesmo elementos maiores. O nível de circuito eletrônico pode, por sua vez, ser subdividido em detalhes em nível de transistor, tais como quais estruturas básicas de construção de portões são usadas e quais tipos de implementação lógica (estática/dinâmica, número de fases, etc.) são escolhidos, além do projeto lógico real usado para construí-los.
Alguns pontos importantes:
- Uma única microarquitetura, especialmente se incluir microcódigo, pode ser usada para implementar muitos conjuntos de instruções diferentes, por meio da mudança da loja de controle. Isto pode ser bastante complicado, porém, mesmo quando simplificado por microcódigos e/ou estruturas de tabela em ROMs ou PLAs.
- Duas máquinas podem ter a mesma microarquitetura e, portanto, o mesmo diagrama de blocos, mas implementações de hardware completamente diferentes. Isto gerencia tanto o nível do circuito eletrônico quanto ainda mais o nível físico de fabricação (de ambos os circuitos integrados e/ou componentes discretos).
- Máquinas com diferentes microarquiteturas podem ter a mesma arquitetura de conjunto de instruções, e assim ambos são capazes de executar os mesmos programas. Novas microarquiteturas e/ou soluções de circuitos, juntamente com os avanços na fabricação de semicondutores, são o que permite que as novas gerações de processadores alcancem maior desempenho.
Descrições simplificadas
Uma descrição de alto nível muito simplificada - comum em marketing - pode mostrar apenas características bastante básicas, tais como largura de ônibus, juntamente com vários tipos de unidades de execução e outros grandes sistemas, tais como previsão de ramificação e memórias de cache, retratados como blocos simples - talvez com alguns atributos ou características importantes anotados. Alguns detalhes relativos à estrutura do gasoduto (como buscar, decodificar, atribuir, executar, escrever de volta) também podem, às vezes, ser incluídos.
Aspectos da microarquitetura
O datapath de encanamento é o projeto de datapath mais comumente utilizado hoje em dia na microarquitetura. Esta técnica é utilizada na maioria dos microprocessadores, microcontroladores e DSPs modernos. A arquitetura pipelinada permite que múltiplas instruções se sobreponham na execução, muito parecido com uma linha de montagem. A tubulação inclui várias etapas diferentes que são fundamentais nos projetos de microarquitetura. Algumas dessas etapas incluem a busca de instruções, a decodificação de instruções, a execução e a escrita de volta. Algumas arquiteturas incluem outras etapas como o acesso à memória. O projeto de dutos é uma das tarefas centrais da microarquitetura.
As unidades de execução também são essenciais para a microarquitetura. As unidades de execução incluem unidades lógicas aritméticas (ALU), unidades de ponto flutuante (FPU), unidades de carga/armazém e previsão de ramo. Estas unidades executam as operações ou cálculos do processador. A escolha do número de unidades de execução, sua latência e rendimento são tarefas importantes de projeto microarquitetônico. O tamanho, latência, rendimento e conectividade das memórias dentro do sistema também são decisões microarquitetônicas.
As decisões de projeto em nível de sistema, como a inclusão ou não de periféricos, como controladores de memória, podem ser consideradas parte do processo de projeto microarquitetônico. Isto inclui decisões sobre o nível de desempenho e conectividade desses periféricos.
Ao contrário do projeto arquitetônico, onde um nível de desempenho específico é o objetivo principal, o projeto microarquitetônico dá mais atenção a outras restrições. A atenção deve ser dada a questões como:
- Área/custo do chip.
- Consumo de energia.
- Complexidade lógica.
- Facilidade de conectividade.
- Manufatura.
- Facilidade de depuração.
- Testabilidade.
Conceitos Micro-Arquitetônicos
Em geral, todas as CPUs, microprocessadores de chip único ou implementações multi-chip executam programas executando os seguintes passos:
- Leia uma instrução e decodifique-a.
- Encontre quaisquer dados associados que sejam necessários para processar a instrução.
- Processar a instrução.
- Escreva os resultados.
Complicando esta série de passos simples é o fato de que a hierarquia de memória, que inclui cache, memória principal e armazenamento não volátil como discos rígidos, (onde estão as instruções e dados do programa) sempre foi mais lenta do que o próprio processador. A etapa (2) muitas vezes introduz um atraso (em termos de CPU, muitas vezes chamado de "stall") enquanto os dados chegam através do barramento do computador. Uma grande quantidade de pesquisas tem sido colocada em projetos que evitam estes atrasos tanto quanto possível. Ao longo dos anos, um objetivo central do projeto era executar mais instruções em paralelo, aumentando assim a velocidade efetiva de execução de um programa. Estes esforços introduziram uma lógica complicada e estruturas de circuitos. No passado, tais técnicas só podiam ser implementadas em mainframes ou supercomputadores caros, devido à quantidade de circuitos necessários para essas técnicas. Com o progresso da fabricação de semicondutores, mais e mais dessas técnicas podiam ser implementadas em um único chip semicondutor.
O que se segue é um levantamento das técnicas microarquitetônicas que são comuns nas CPUs modernas.
Conjunto de instruções de escolha
A escolha da arquitetura do conjunto de instruções a ser utilizada afeta muito a complexidade da implementação de dispositivos de alto desempenho. Ao longo dos anos, os projetistas de computadores fizeram o melhor para simplificar os conjuntos de instruções, a fim de permitir implementações de maior desempenho, poupando esforço e tempo dos projetistas para recursos que melhoram o desempenho em vez de desperdiçá-los com a complexidade do conjunto de instruções.
O projeto do conjunto de instruções progrediu dos tipos CISC, RISC, VLIW, EPIC. As arquiteturas que tratam do paralelismo de dados incluem SIMD e Vetores.
Tubulação de instrução
Uma das primeiras e mais poderosas técnicas para melhorar o desempenho é o uso da tubulação de instrução. Os primeiros projetos do processador executaram todas as etapas acima em uma instrução antes de passar para a próxima. Grandes porções do circuito do processador eram deixadas ociosas em qualquer etapa; por exemplo, o circuito de decodificação de instruções seria ocioso durante a execução e assim por diante.
As tubulações melhoram o desempenho ao permitir uma série de instruções para trabalhar ao mesmo tempo através do processador. No mesmo exemplo básico, o processador começaria a decodificar (passo 1) uma nova instrução enquanto a última aguardava por resultados. Isto permitiria que até quatro instruções estivessem "em vôo" ao mesmo tempo, fazendo com que o processador parecesse quatro vezes mais rápido. Embora qualquer instrução leve o mesmo tempo para ser completada (ainda há quatro passos), a CPU como um todo "se aposenta" muito mais rapidamente e pode ser executada a uma velocidade de relógio muito mais alta.
Cache
As melhorias na fabricação de chips permitiram que mais circuitos fossem colocados no mesmo chip, e os projetistas começaram a procurar maneiras de usá-lo. Uma das formas mais comuns era adicionar uma quantidade cada vez maior de memória cache no chip. O cache é uma memória muito rápida, memória que pode ser acessada em poucos ciclos, em comparação com o que é necessário para falar com a memória principal. A CPU inclui um controlador de cache que automatiza a leitura e escrita a partir do cache, se os dados já estiverem no cache ele simplesmente "aparece", enquanto que se não for o processador está "paralisado" enquanto o controlador de cache o lê dentro.
Os projetos da RISC começaram a adicionar cache em meados dos anos 80, muitas vezes apenas 4 KB no total. Este número cresceu com o tempo, e as CPUs típicas agora têm cerca de 512 KB, enquanto as CPUs mais potentes vêm com 1 ou 2 ou mesmo 4, 6, 8 ou 12 MB, organizadas em múltiplos níveis de uma hierarquia de memória. De modo geral, mais cache significa mais velocidade.
Caches e oleodutos eram uma combinação perfeita um para o outro. Anteriormente, não fazia muito sentido construir um oleoduto que pudesse funcionar mais rápido do que a latência de acesso da memória de dinheiro fora do chip. Ao invés disso, o uso de memória cache on-chip significava que um pipeline poderia funcionar na velocidade da latência de acesso ao cache, um período de tempo muito menor. Isto permitiu que as freqüências de operação dos processadores aumentassem a uma velocidade muito maior do que a da memória off-chip.
Predição de filiais e execução especulativa
As barracas de tubulação e os fluxos devido aos galhos são as duas coisas principais que impedem a obtenção de maior desempenho através do paralelismo do nível de instrução. Desde o momento em que o decodificador de instruções do processador descobriu que encontrou uma instrução de ramificação condicional até o momento em que o valor do registro de salto decisivo pode ser lido, a tubulação pode ficar paralisada por vários ciclos. Em média, cada quinta instrução executada é uma ramificação, o que representa uma grande quantidade de paralelismo. Se a ramificação for tomada, é ainda pior, pois então todas as instruções subseqüentes que estavam na tubulação precisam ser enxaguadas.
Técnicas como a previsão de ramos e a execução especulativa são utilizadas para reduzir as penalidades desses ramos. A previsão do ramo é onde o hardware faz suposições instruídas sobre se um determinado ramo será tomado. O palpite permite que o hardware preveja as instruções sem esperar pela leitura do registro. A execução especulativa é um aperfeiçoamento adicional no qual o código ao longo do caminho previsto é executado antes que se saiba se o ramo deve ou não ser tomado.
Execução fora de ordem
A adição de caches reduz a freqüência ou a duração das baias devido à espera de dados da hierarquia de memória principal, mas não se livra completamente dessas baias. Em projetos iniciais, uma falta de cache forçaria o controlador de cache a empatar o processador e esperar. É claro que pode haver alguma outra instrução no programa cujos dados estejam disponíveis no cache naquele ponto. A execução fora de ordem permite que essa instrução pronta seja processada enquanto uma instrução mais antiga aguarda no cache, depois reordena os resultados para fazer parecer que tudo aconteceu na ordem programada.
Superscalar
Mesmo com toda a complexidade e os portões necessários para suportar os conceitos descritos acima, as melhorias na fabricação de semicondutores logo permitiram a utilização de ainda mais portões lógicos.
No esquema acima, o processador processa partes de uma única instrução de cada vez. Os programas de computador poderiam ser executados mais rapidamente se várias instruções fossem processadas simultaneamente. Isto é o que os processadores de super-escalas conseguem, ao replicar unidades funcionais como ALUs. A replicação de unidades funcionais só foi possível quando a área do circuito integrado (algumas vezes chamado de "die") de um processador de uma única emissão não mais esticou os limites do que poderia ser fabricado de forma confiável. No final dos anos 80, os projetos de super-escalares começaram a entrar no mercado.
Em projetos modernos é comum encontrar duas unidades de carga, uma loja (muitas instruções não têm resultados para armazenar), duas ou mais unidades matemáticas inteiras, duas ou mais unidades de ponto flutuante, e muitas vezes uma unidade SIMD de algum tipo. A lógica de emissão de instruções cresce em complexidade ao ler em uma enorme lista de instruções da memória e entregá-las às diferentes unidades de execução que estão ociosas naquele ponto. Os resultados são então coletados e reordenados no final.
Renomeação do registro
A renomeação de registros refere-se a uma técnica utilizada para evitar a execução seriada desnecessária de instruções do programa, devido à reutilização dos mesmos registros por essas instruções. Suponhamos que tenhamos grupos de instruções que utilizarão o mesmo registro, um conjunto de instruções é executado primeiro para deixar o registro para o outro conjunto, mas se o outro conjunto for atribuído a um registro similar diferente, ambos os conjuntos de instruções podem ser executados em paralelo.
Multiprocessamento e multithreading
Devido à distância crescente entre as freqüências de operação da CPU e os tempos de acesso DRAM, nenhuma das técnicas que melhoram o paralelismo de nível de instrução (ILP) dentro de um programa pôde superar as longas paradas (atrasos) que ocorreram quando os dados tiveram que ser buscados na memória principal. Além disso, o grande transistor conta e as altas freqüências de operação necessárias para as técnicas mais avançadas de ILP exigiam níveis de dissipação de energia que não podiam mais ser resfriados a baixo custo. Por estas razões, novas gerações de computadores começaram a utilizar níveis mais altos de paralelismo que existem fora de um único programa ou thread de programa.
Esta tendência é às vezes conhecida como "throughput computing". Esta idéia teve origem no mercado mainframe onde o processamento de transações on-line enfatizava não apenas a velocidade de execução de uma transação, mas a capacidade de lidar com um grande número de transações ao mesmo tempo. Com aplicações baseadas em transações, tais como roteamento de rede e web-site servindo em grande escala na última década, a indústria de computadores voltou a enfatizar a capacidade e os problemas de throughput.
Uma técnica de como este paralelismo é alcançado é através de sistemas de multiprocessamento, sistemas de computador com múltiplas CPUs. No passado, isto era reservado para mainframes high-end, mas agora servidores multiprocessadores de pequena escala (2-8) tornaram-se comuns para o mercado de pequenas empresas. Para grandes corporações, os multiprocessadores de grande escala (16-256) são comuns. Mesmo computadores pessoais com CPUs múltiplas têm aparecido desde os anos 90.
Os avanços na tecnologia de semicondutores reduziram o tamanho do transistor; surgiram CPUs de múltiplos núcleos onde várias CPUs são implementadas no mesmo chip de silício. Inicialmente utilizadas em chips visando mercados embutidos, onde CPUs mais simples e menores permitiriam múltiplas instantâneos para caber em um único pedaço de silício. Em 2005, a tecnologia de semicondutores permitiu a fabricação em volume de CPUs CMP dual high-end de mesa. Alguns projetos, como o UltraSPARC T1, usavam um projeto mais simples (escalar, por ordem) para caber mais processadores em um único pedaço de silício.
Recentemente, outra técnica que tem se tornado mais popular é a multithreading. Em multithreading, quando o processador tem que buscar dados na memória lenta do sistema, em vez de empatar para que os dados cheguem, o processador muda para outro programa ou thread de programa que está pronto para executar. Embora isto não acelere um programa/ thread em particular, aumenta o rendimento geral do sistema ao reduzir o tempo em que a CPU está ociosa.
Conceitualmente, a multi-tarefa equivale a uma mudança de contexto no nível do sistema operacional. A diferença é que uma CPU multithreading pode fazer uma troca de rosca em um ciclo de CPU em vez das centenas ou milhares de ciclos de CPU que uma troca de contexto normalmente requer. Isto é conseguido através da replicação do hardware estatal (como o arquivo de registro e o contador de programas) para cada thread ativa.
Uma outra melhoria é a multi-tarefa simultânea. Esta técnica permite que as CPUs superscalares executem instruções de diferentes programas/threads simultaneamente no mesmo ciclo.
Páginas relacionadas
- Microprocessador
- Microcontrolador
- Processador multi-core
- Processador de sinal digital
- Projeto de CPU
- Datapath
- paralelismo a nível de instrução (ILP)
Perguntas e respostas
P: O que é microarquitetura?
R: Microarquitetura é uma descrição do circuito elétrico de um computador, unidade central de processamento, ou processador de sinais digitais, que é suficiente para descrever completamente o funcionamento do hardware.
P: Como os estudiosos se referem a esse conceito?
R: Os estudiosos usam o termo "organização de computadores" quando se referem à microarquitetura.
P: Como as pessoas da indústria de computadores se referem a esse conceito?
R: As pessoas da indústria de computadores dizem mais freqüentemente "microarquitetura" quando se referem a esse conceito.
P: Quais são os dois campos que compõem a arquitetura de computadores?
R: Microarquitetura e arquitetura de conjunto de instruções (ISA) constituem juntos o campo da arquitetura de computadores.
P: O que significa ISA?
R: ISA significa "Instruction Set Architecture" (Arquitetura de conjunto de instruções).
P: O que significa µarch? R: µArch significa Microarquitetura.
Artigos relacionados
Autor
AlegsaOnline.com Microarquitetura Leandro Alegsa
URL: https://pt.alegsaonline.com/art/64586
Fontes
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture